字符串和数字之间的相互转换
数字转为字符串:
方法1:使用sprintf
1 | int num=10; |
方法2:使用最原始的方式进行转换
1 | int num=10; |
方法3:to_string函数
1 | int num=10; |
方法4:_itoa函数
1 | int num=10; |
字符串转数字:**
方法1:sscanf
1 | char str[]="100"; |
方法2:atoi函数
1 | char str[]="100"; |
方法3:
1 | string str="100"; |
转载请标明出处,谢谢
字符串和数字之间的相互转换
数字转为字符串:
方法1:使用sprintf
1 | int num=10; |
方法2:使用最原始的方式进行转换
1 | int num=10; |
方法3:to_string函数
1 | int num=10; |
方法4:_itoa函数
1 | int num=10; |
字符串转数字:**
方法1:sscanf
1 | char str[]="100"; |
方法2:atoi函数
1 | char str[]="100"; |
方法3:
1 | string str="100"; |
转载请标明出处,谢谢
每次学完数组之后就是当时学完,当时特别的清楚,可是过了几天却就忘,今天我就把一维数组二维数组的知识点总结如下:
1.一维数组常见用法如下:
1.1一维数组的数组名称:
除了两种特殊的情况以外,都是指向数组第一个元素的指针。
特殊情况1:sizeof(数组名)求得的是整个数组的大小
特殊情况2:对数组名取地址,是一维的数组指针,它的步长整个一维数组的长度
一维数组名是一维数组的首地址,等于&arr[0](第一个元素的地址)
1.2一维数组指针的定义方式:
1 | int arr[5] = { 1, 2, 3, 4, 5 }; |
2.二维数组常见用法
2.1 二维数组名
二维数组名 除了两种特殊情况外,是指向第一个一维数组的 数组指针(int(*p)【3】)
特殊情况1:sizeof 统计二维数组大小
特殊情况2:对数组名称取地址 int(*p)【3】【3】 = &arr
二维数组的数组指针跟一维数组指针的定义方式类似:只是多了个维度(int(*p)【3】【3】)。
1 | int arr2[][3] = { {1,2,3},{4,5,6},{7,8,9} }; |
3 不要放回局部变量的地址,字符串也不行
1 | //出现乱码,因为str是局部变量开辟在栈区,在当前函数结束就被释放,我们无权操作 |
转载:请标明原创,谢谢
–创建数据库
create database test
on primary
(name=’test’,–主数据文件的逻辑名称
filename=’D:\shujuku\test.mdf’–主数据文件的物理名称及地址
size=3mb,–主数据文件的初始大小
maxsize=10mb,–主数据文件的最大值
filegrowth=3mb–主数据文件的增长率
)
log on–日志文件
(
name=’test’,
filename=’D:\shujuku\test.ldf’,
size=2mb,
maxsize=100mb,
filegrowth=15%
)
use test–使用test数据库
–创建表
create table ClassIfo
(cId int not null primary key identity(1,1),
cTitle nvarchar(10)
)
创建表
select * from ClassIfo
use test
create table StudentInfo
(
sId int not null primary key identity(1,1),
sName nvarchar(10) not null,
sSex bit default(0),
sBirth date,
sPhone char(11),
sEamil varchar(20),
cid int not null,
foreign key(cid) references ClassIfo(cid)
)
–插入 insert into 表名 values
select * from ClassIfo
insert ClassIfo(cTitle) values(‘张三’)
insert into ClassIfo values(‘张三’),(‘李四’)
insert into ClassIfo values(‘张三’,’李四’)
insert ClassIfo(cTitle) values(‘张三’)
insert into ClassIfo values(‘张三’),(‘李四’)
–修改操作update 表名 set 列名=‘修改的值’,alter table 表名 相应指令
select * from ClassIfo
–为所有的列进行修改
update ClassIfo set cTitle=’展示柜’
–为指定的行进行修改
update ClassIfo set cTitle=’李四’ where cId>2
–删除操作 delete 表名 where
select * from ClassIfo
delete ClassIfo where cid>2
–清空表 truncate table 表名
–查询 select 列名 as 别名,列名 as 别名 from 表名 as 别名(as可以省略)
–取别名 as
select ctitle as 标题 from ClassIfo as al
select al.ctitle astitle from ClassIfo al
–select top n * from classinfo 查询前n行,所有列
–select top n percent * from classinfo 查询前百分之的行的所有列
insert into ClassIfo values(‘张三’),(‘李四’),(‘王五’)
select top 3 *
from ClassIfo
–排序 order by 列名 asc,列名 asc(从小到大)/desc(从大到小),写在from的后面,如果一个列名相等,在比较另外一个列名
select * from ClassIfo
order by cId desc
–distinct 消除重复行
select distinct cid from ClassIfo
–条件查询 写在where后面
select ctitle from ClassIfo
where cId=4
–取出1班或3班的学生的信息
select * from ClassIfo
where cId in(1,3) –in指的是1或3并不是连续的
–模糊查询
–查找姓张的学生信息,%代表一个字符或多个字符
select * from StudentInfo
where sname like ‘张%’
–查询姓名为两个字的姓黄的学生信息,表示一个字符,[^0-2],表示除了0-2之外的所有的数
select * from StudentInfo
where sname like ‘黄‘
–查询一个数值为空的条件用is不能用=
–多表连接查询,两个表之间有对应的关系,可以是内连接,也可以是外连接 select *from classinfo inner join studentinfo on classinfo.cid=studentinfo.cid
–right join–右连接匹配右边边特有的数据
–left join–左连接,匹配左边特有的数据
–full join–完全外连接,同时匹配左边和右边特有的数据
–inner join–内连接,匹配两表中完全匹配的数据
select cl.sname,st.ctitle from ClassIfo as cl inner join studentinfo on cl.cit=st.cid
select * from StudentInfo
–多张表的连接查询,classinfo表和studentinfo表有关系,studentinfo和subjectinfo表有关系,依次类推
–查询三张表的所有信息
select * from classinfo as cl
inner join studentinfo as stu on cl.cid=stu.cid
inner join subjectinfo as sub on stu.cid=sub.cid
–聚合函数
sum(最大值)、avg(平均值)、min(最小值)、count()统计所有行数的个数
–查询学生表中一共有多少人
select count() as count1 from studentinfo
–查询班级编号为一的人数
select count(*) as count1 from studentinfo where cid=1
–使用count的时候,null不会计数
select count(sphone) from studentinfo
–查询分数最高的成绩
select max(score) from scoreinfo
–查询一班中分数最高的成绩
select max(score) from scoreinfo where cid=1
–开窗函数:over,放在聚合函数后面,作用是将聚合函数统计的信息分布到每一行中
–统计信息分布到行中
select scoreinfo.,avg(score) from scoreinfo where subid=1 –会报错
–正确写法如下
select scoreinfo.,avg(score) over() from scoreinfo where subid=1
–分组:group by
–统计每个班的男女生人数
select sgender,cid count() from studentinfo
group by sgender,cid
–统计学生编号大于2的各班级的男女生人数
select cid,sgender,count() from studentinfo
where sid>2 group by cid,sgender
–分完组之后,如果还想对分组的内容进行筛选,在group by 后面加having加条件,haveing不能使用未参与分组的列
–也可以使用in的方法,having count() in(2,5,8),where中不能使用聚合函数
–统计学生编号大于2的各班级的男女生人数大于3的信息
select cid,sgender,count() from studentinfo
where cid>2 group by cid,sgender having count(*)>3
–isnull(类型,’替换内容’)的用法
–查询英语成绩,如果英语成绩为空则显示缺考
select isnull(convert(varchar(20),singlish(所查询的列名)),’缺考’) from studentinfo
–完整的sql语句及执行顺序
select distinct top n *from
table1 join table2 on …
where …
group by … having …
order by …
–联合查询 只能是有相同列的两个并且每一个列对应的值类型相同才能查询 union(并集)、union all(所有的数,包括重复的数)
–except(补集,找它左边特有的部分),intersect(交集)
–查询cid和sid的交集
select cid from classinfo
intersect
select sid from studentinfo
–将横表变为纵表
select ‘最高成绩’ as 描述信息,max(tenglish) as 成绩 from studentinfo
union
select ‘最低成绩’ as 描述信息,min(tenglish) as 成绩 from studentinfo
–快速备份表 :select 列名 into 备份表名 from 源表名 如果备份表不存在,则会新建一个表,表的结构完全一致
--但是不会包含约束条件,如果只想包含表的结构不包含数据可以加一个不存在的条件
--向已有的表中,备份另一个表 insert into 备份表名 select 列名 from 源表名–将数据备份到一个不存在的test表中
select * into test from classinfo
–将数据备份到一个不存在的test表中,只要结构
select * into test from classinfo where 1=2
–或
select top 0 * into test from classinfo
–将数据备份到一个存在的表中
insert into test select cid from calssinfo
–类型转换:select cast(类型1(被转换) as 类型2(目标))
select convert(数据类型1(目标),数据类型2(被转换))–将89.0000转换为89.0
select cast(89.0000 as decimal(3,1))
–计算字符的ascii值 select ascii(‘字符’)
–根据ascii的值转到字符 select char(数值)
–返回字符串长度 select len(‘字符串’)
–将字符串转换为小写 select lower(‘大写’),将字符串转换为大写 select upper(‘小写’)
–截取字符串
–从左边截取字符串
select left(‘字符串’,2)–从左边开始截取两个字符
–从右边截取字符串
select right(‘字符串’,2)–从右边截取两个字符串
select substring(‘字符串’,2,3)–从第二个字符开始,一共截取3个字符
–切掉空格
select ‘哈哈’+ltrim(‘ hello world’)–去掉左边的空格 哈哈hello world
select ‘哈哈’+rtrim( ‘hello’ )–去掉右边的空格 哈哈 hello
–去空格需要嵌套
select ‘哈哈’+rtrim(ltrim(‘ hello world’))–去掉左边的空格 哈哈hello world
–视图(对select语句进行封装,方便使用)
–语法 creat view 视图名 as select的查询语句
–子查询(在一个查询中嵌套另一个查询)关键字有=,in,exits(in的效率低于exits)
–查询参加了考试的学生的信息
select * from studentinfo
where sid in(select distinct stuid from scoreinfo)
–或
select * from studentinfo
where sid exits(select * from scoreinfo where studentinfo.stuid=scoreinfo.sid)
–case语句 语法
–查询学生的所有信息,并且判断该学生是否及格
select *, 是否及格=case
when tenglish>60 then ‘及格’
else ‘差’
end from scoreinfo–可以判断一个区间的值 >=
–case语句第二种表述方式,但是不能用于区间
select *,是否及格=case tenglishscore when 60 then ‘及格’
when 59 then ‘不及格’
else ‘优秀’
end from scoreinfo –不能用域区间判断
–异常处理 :begin try …
end try
如果上面的语句有错误则执行下面的语句
begin catch …
end catch
–事务 判断一任务是否完成,没有完成则会回到初始的状态
–语法:begin transaction … –开始事务
comit transaction –提交事务,没有错才会执行,执行完了以后就不会执行下面的语句
rollback transaction … –回滚,出错后执行该语句
–锁 防止对数据的误操作
语法:在事务的基础上把提交操作,这样即使修改了还是会回到初始状态
begin transaction …
rollback transaction –回滚
–存储过程 将select语句封装成一个存储过程,语法:create proc 名称 参数列表 as begin … end
调用:exec 名称 参数列表
–将字符串去空格
declare @temp varchar(100)
set @temp=’ abc ‘
select ltrim(rtrim(@temp))
–转换成存储过程
create proc trim
@str1 varchar(100)
as
begin select ltrim(rtrim(@str1))
end
1 |
|
1 |
|
1 |
|
1 |
|
1 |
|
1 |
|
1 |
|
1 | //斐波那契数列指的是这样一个数列 1, 1, 2, 3, 5, 8, 13。。。。。 |
1 |
|
1 |
|
有问题疑问请留言,我会第一时间解答,谢谢
由于空间有限剩下的请访问:
https://github.com/zhajianliang/c-c-.git
转载求标明出处:
1.目标文件:依赖文件(可以省去预编译,汇编,编译)
[Tab键]指令
2.第一个目标文件是我们的最终目标,下面的hello是我们的最终目标。
3.伪目标:.PHONY:
rm -rf hello.S hello.i hello.o(指定删除你不需要的文件)
4.Makefile文件书写
1 | hello:hello.o //hello是目标文件,hello.i是依赖文件 |
在第一层的基础上进行变量替换:
变量 = (替换) +=(追加) :=(恒等于)
示例:
1 | VAL=hello //替换 |
%.c(任意的.c文件 *.c(所有的.c文件)
1 | %.c:%.o |
最常见的几个指令:
$@ 所有的目标文件 $^ 所有的依赖文件 $< 所有依赖文件的第一个文件
希望对你们有帮助,制作不易,转载请标明出处:
指令
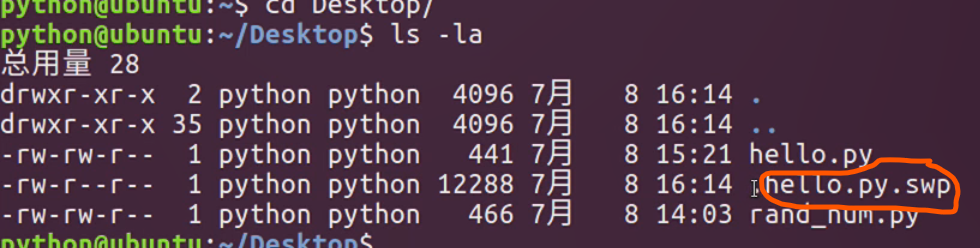
1 | vi test.c |
如果该文件存在则打开,该文件不存在则新建
指令:
1 | vi test.c +16 |
该指令会打开,并跳转到test.c的第16行,如果只有+号,而没有16,则会直接定位到文件末尾。
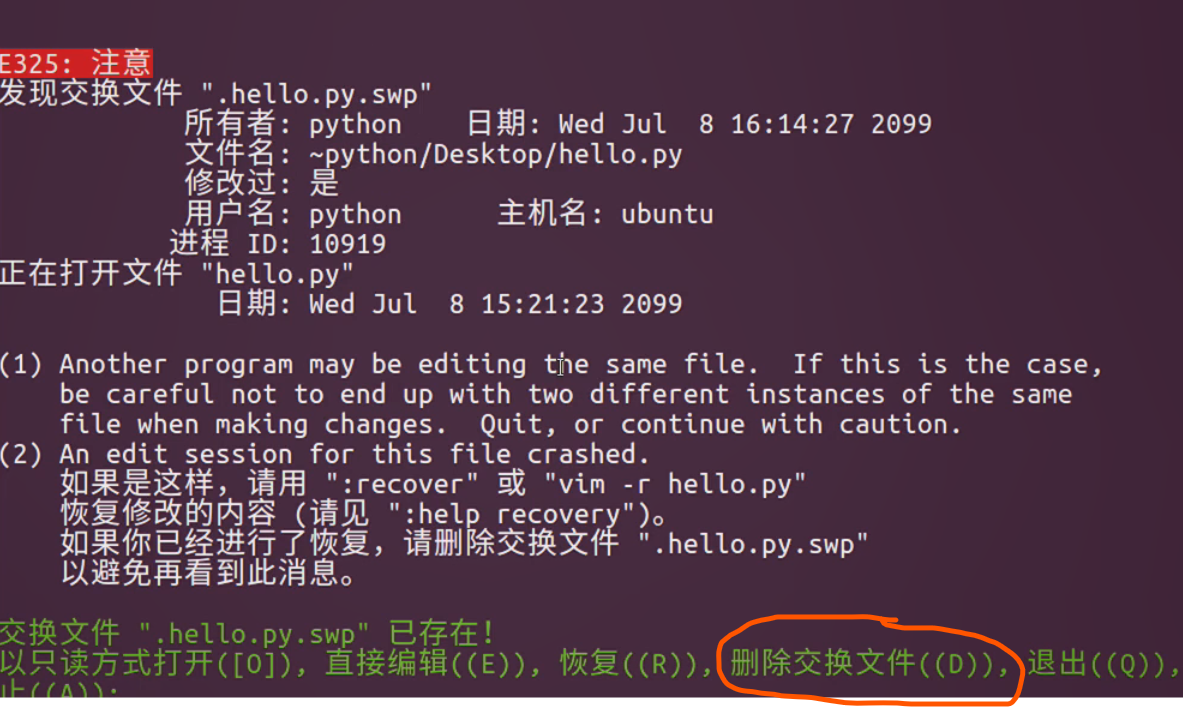
Ctrl+b 向后翻页,Ctrl+f向前翻页
H 屏幕顶部
M 屏幕中间
L 屏幕底部
{ 上一段
} 下一段
指令
1 | % |
指令
1 | ma//给一代码标记为a |
m后面的值可以使a-z或A-Z.
v 可视模式 从光标位置开始按照正常模式选择文本
V 可视行模式 选中光标经过的完整行
Ctrl+v 可视块模式 垂直方向选中文本
u 恢复上次的命令
Ctrl+r 恢复撤销的命令
x 删除光标所在的字符
d+移动命令 删除移动命令中对应的内容
dd 删除光标所在的整行
ndd 删除从光标所在的行开始的n行
D 从光标位置开始删除到行尾
y 复制一个字符
yy 复制光标所在的一整行
nyy 复制光标所在的行复制n行
p 进行粘贴
注意:vi中的文本缓冲区与系统中的剪贴板不是同一个
在其他软件中用Ctrl+c复制的内容不能通过p来张贴
可以在编辑模式中通过右键粘贴
r 替换当前字符
R 替换当前行光标前的字符 会进入替换吗模式,替换完成后按ESC回到命令模式
1 | << //向右缩进 |
1 | /str //注意str为你所要查找的内容 |
确定替换命令
1 | :%s/旧文本/新文本/gc //会提示是否替换命令 |
y替换,n不替换,a全部替换,q退出替换,l替换最后一个
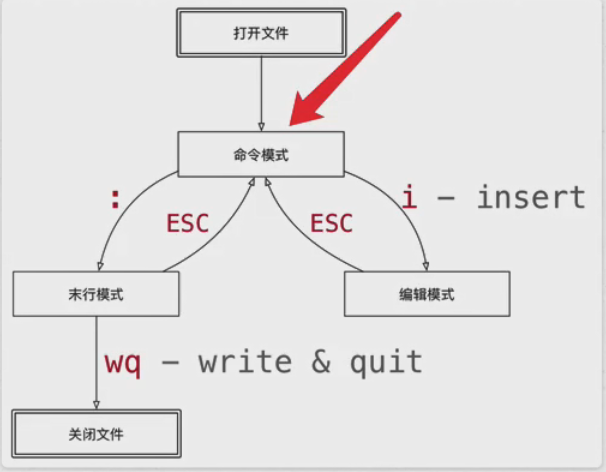
i 在光标所在字符前插入文本
I 在行首插入文本
a 在光标所在字符后插入文本
A 在行尾插入文本
o 在当前行后面插入一个空行
O 在当前行前面插入一个空行
:e 文件名 打开并编辑这个文件
:e . 会打开内置的文件浏览器,可以打开自己想要的文件
:n 文件名 新建文件
:w 文件名 另存为,但是仍然编辑当前文件,不会切换
:sp[文件名] 横向增加分屏
:vsp[文件名] 纵向增加分屏
切换分屏窗口
先按Ctrl+w再依次进行切换
w 切换到下一个窗口
r 互换窗口
c 关闭当前的窗口
q 退出当前窗口,如果使最后一个窗口则关闭vi
o 关闭其他窗口
转载请标明出处
比较相邻的元素。如果第一个比第二个大,就交换他们两个。
对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。这步做完后,最后的元素会是最大的数。
针对所有的元素重复以上的步骤,除了最后一个。
持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较
C源代码:
1 |
|
首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置。
再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。
重复第二步,直到所有元素均排序完毕。
下面我写了两种,我觉得第一种比较直观易懂
C源代码:
1 |
|
将第一待排序序列第一个元素看做一个有序序列,把第二个元素到最后一个元素当成是未排序序列。从头到尾依次扫描未排序序列,将扫描到的每个元素插入有序序列的适当位置。(如果待插入的元素与有序序列中的某个元素相等,则将待插入元素插入到相等元素的后面。
C源代码:
1 |
|
选择一个增量序列 t1,t2,……,tk,其中 ti > tj, tk = 1;
按增量序列个数 k,对序列进行 k 趟排序;
每趟排序,根据对应的增量 ti,将待排序列分割成若干长度为 m 的子序列,分别对各子表进行直接插入排序。仅增量因子为 1 时,整个序列作为一个表来处理,表长度即为整个序列的长度。
C源代码:
1 |
|
C源代码:
1 |
|
C源代码:
1 |
|
C源代码:
1 |
|
我的github地址:https://github.com/zhajianliang/sort-algorithm.git
个人博客地址:https://zhajianliang.github.io
参考地址:https://zh.wikipedia.org/wiki/%E5%86%92%E6%B3%A1%E6%8E%92%E5%BA%8F
参考地址:https://github.com/hustcc/JS-Sorting-Algorithm/blob/master/1.bubbleSort.md
1.很多小伙伴在学校期间学习C语言用的大多都是vc6.0,对于刚接触vs的小伙伴在用c写代码时难免会与遇到各种问题,比如下面的这个错误:
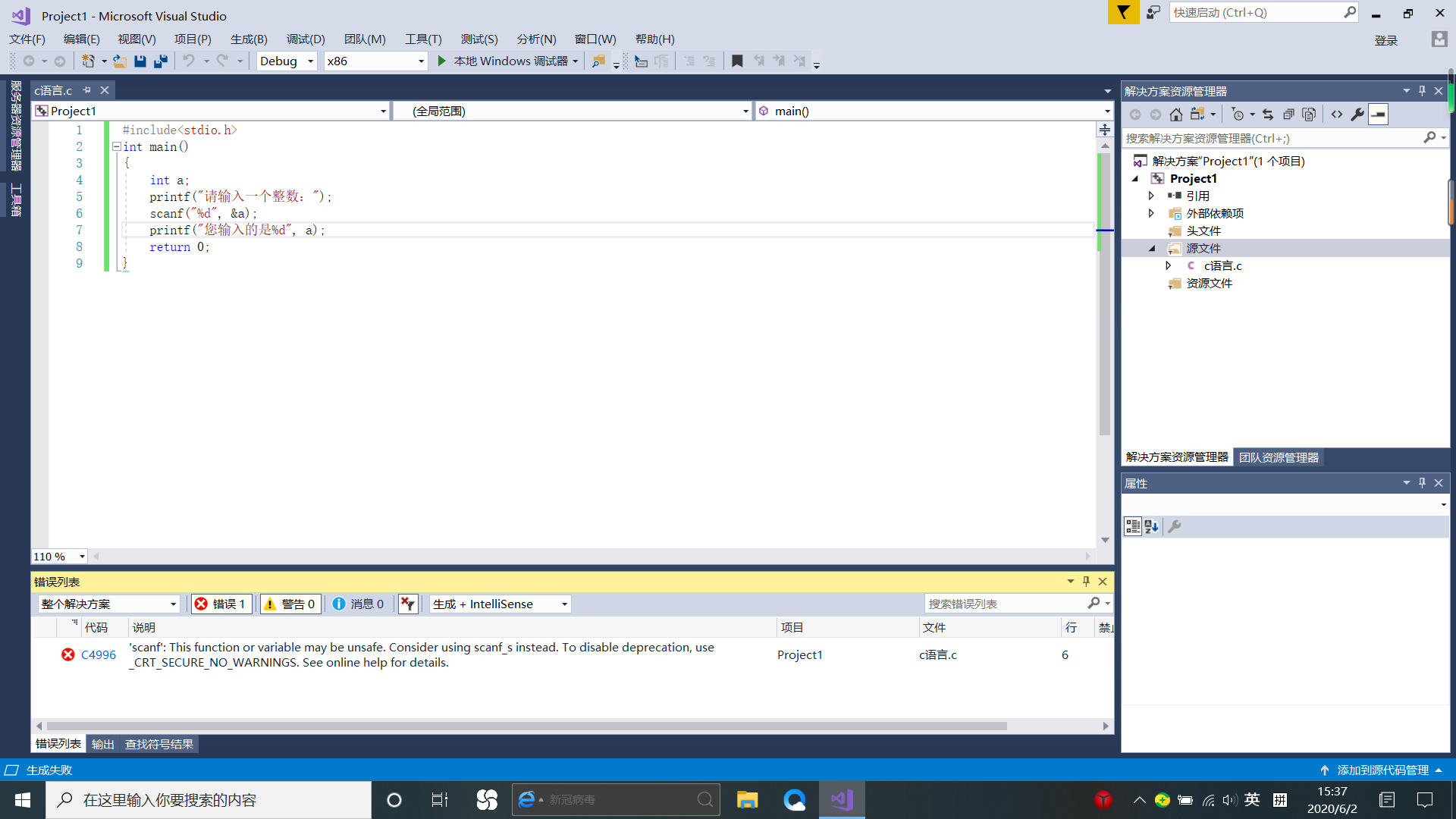
解决该错误的方法一共有三种:
第一种:找到项目,点击项目属性
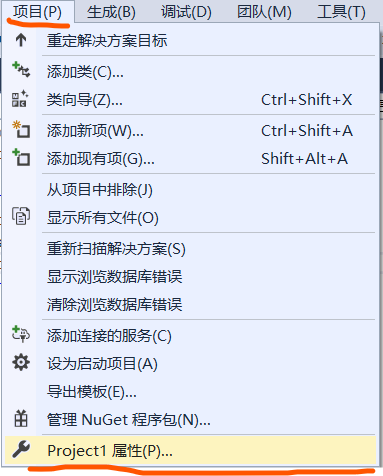
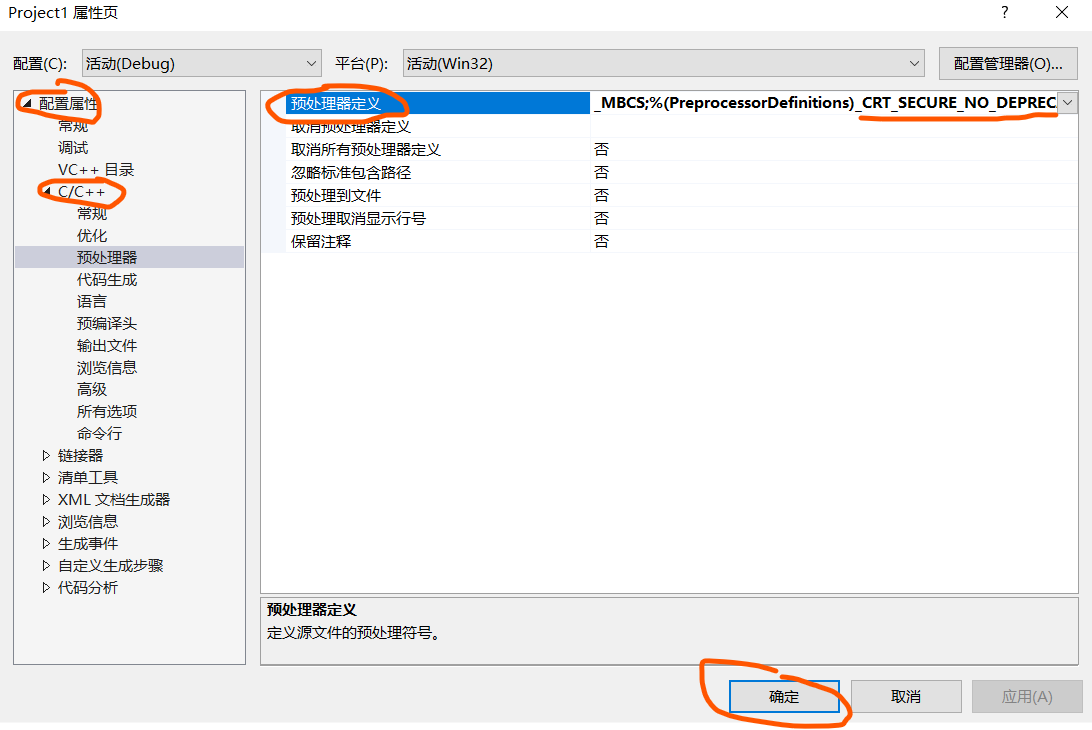
点击配置属性,C/C++,预处理器,预处理器定义然后输入_CRT_SECURE_NO_DEPRECATE,点击确定,配置完成,代码就能正常运行了。
第二种方法:在代码的的开头加上#pragma warning(disable:4996)语句,解决该错误。
第三种方法:将scanf改为scanf_s,解决该错误。
最后希望对你有帮助,加油陌生人。
转载请附原文地址:zhajianliang.github.io
1.创建git的工作区:
新建一个文件夹,进入到该文件夹,鼠标右键,点击进行GIt Bash Here,进行github的基本用户的信息配置(该步骤用于在github显示是谁提交了该文件)及该仓库的初始化指令,下面演示的是用linux的命令行实现,你也可以用鼠标右键创建文件。
指令:
1 | mkdir test//创建test文件; |
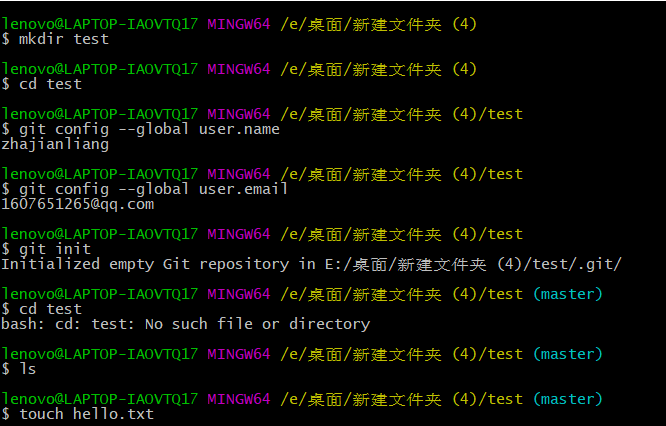
这时我们的test文件夹下就会有
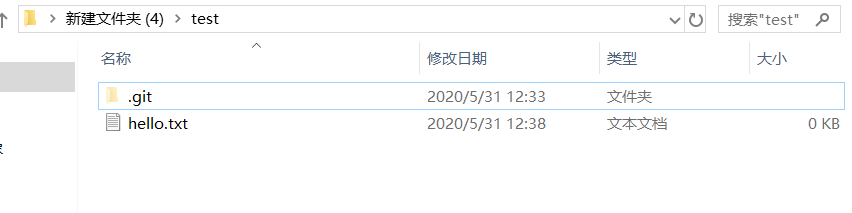
我们的工作区就创建完成了。
2.提交暂存区:
把之前的创建好的工作区的内容提交到暂存区
指令:
1 | git add hello.txt//将hello.txt提交到暂存区 |
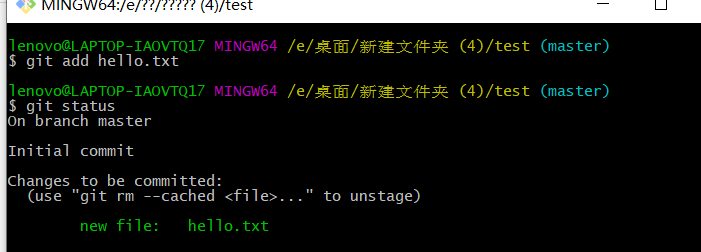
这时test下的hello.txt文件如下,则添加成功

3.将暂存区的内容提交到git仓库:
指令:
1 | add commit -m "添加描述"//将文件提交到仓库 |
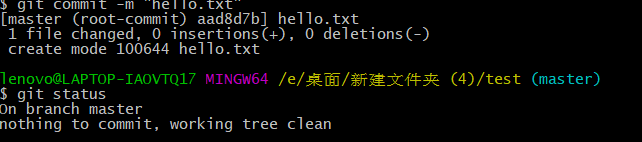
这时test下的hello.txt文件如下,则添加成功

4.修改或删除git仓库中的内容:
修改指令:
1 | vi hello.txt 也可以鼠标右击打开hello.txt //修改文件保存退出 |
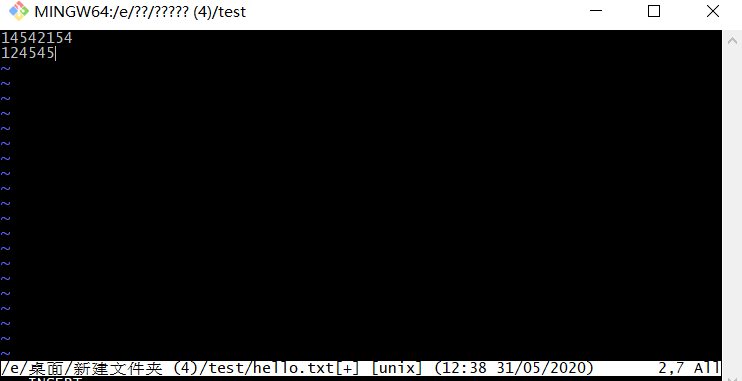
修改以后:

然后再重新添加到暂存区,再提交到Git仓库,修改成功。
删除文件
1 | rm hello.txt //删除文件hello.txt,或用鼠标右键删除文件 |
删除成功
5.把git仓库中的内容推送到github的仓库:
首先在github上新建一个仓库
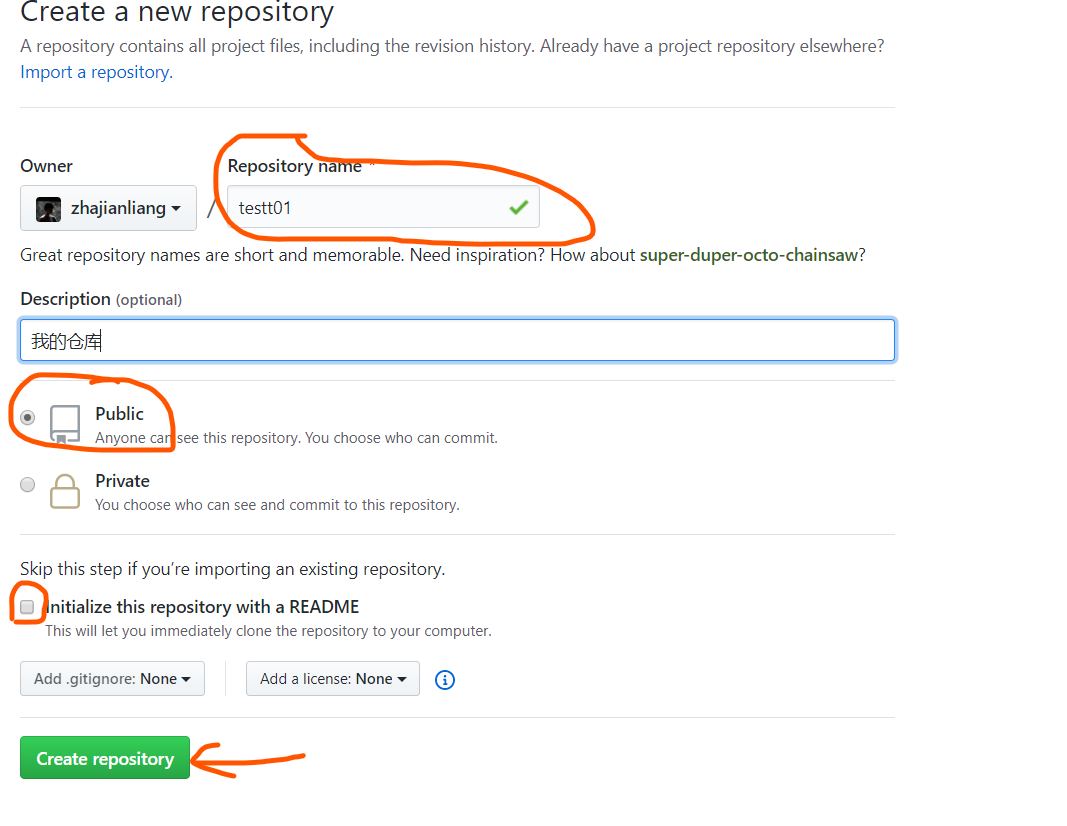
创建完成后,进入到该仓库,复制地址
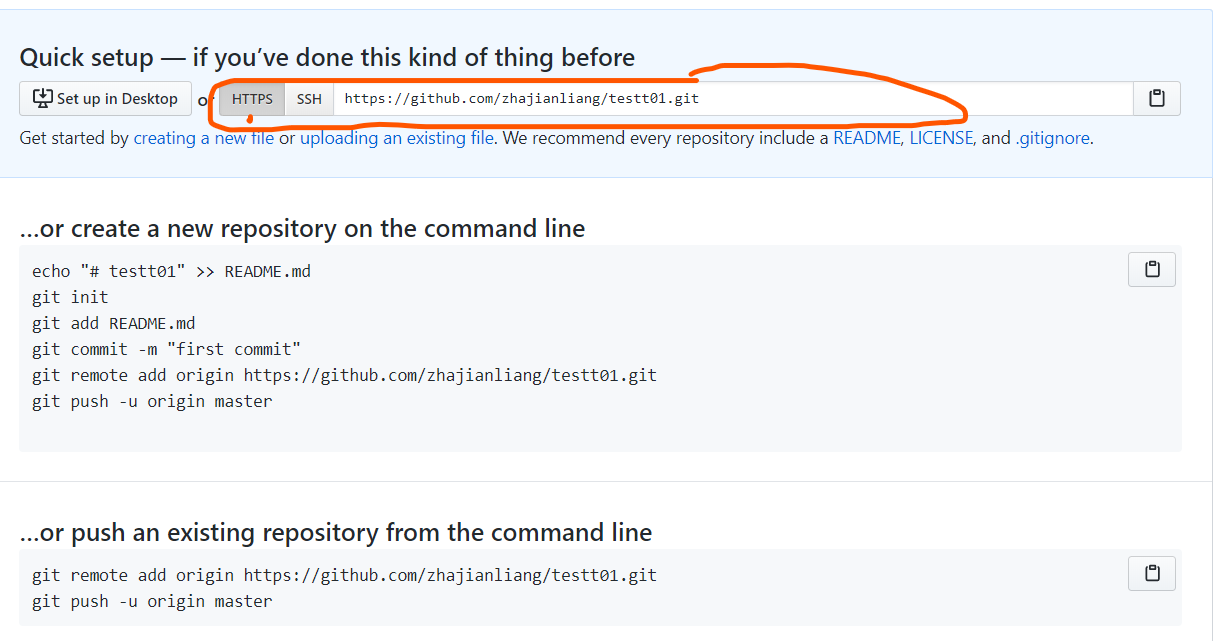
在Git命令窗口输入
1 | git remote add origin https://github.com/zhajianliang/testt01.git |
这时会让你输入自己的用户名和密码
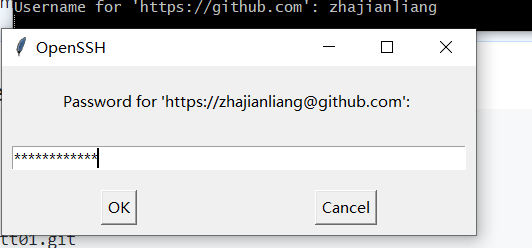
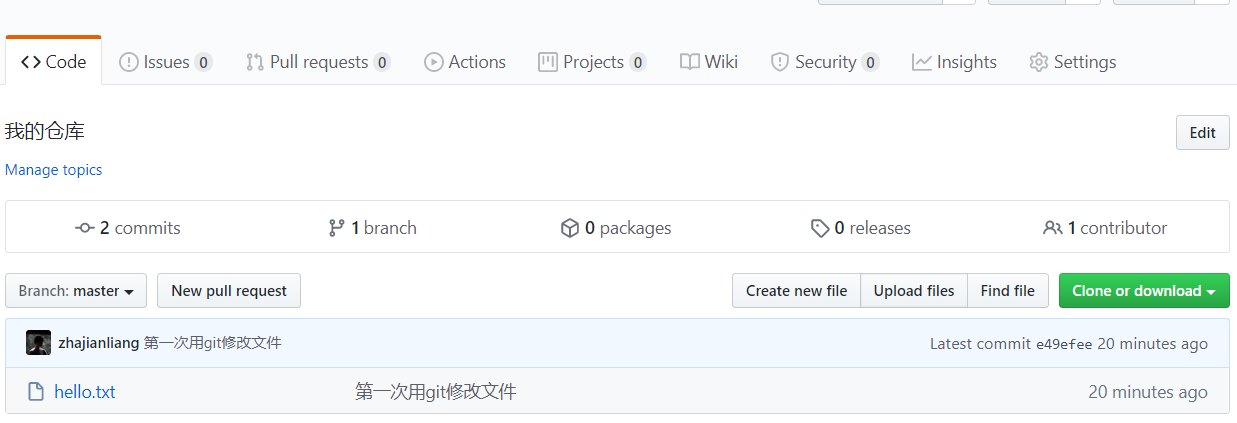
成功推送到自己的github仓库中
2.首先下载安装TortoiseGit,官方网址https://tortoisegit.org/
1.初始化仓库
鼠标右键点击,Git在这里创建版本库
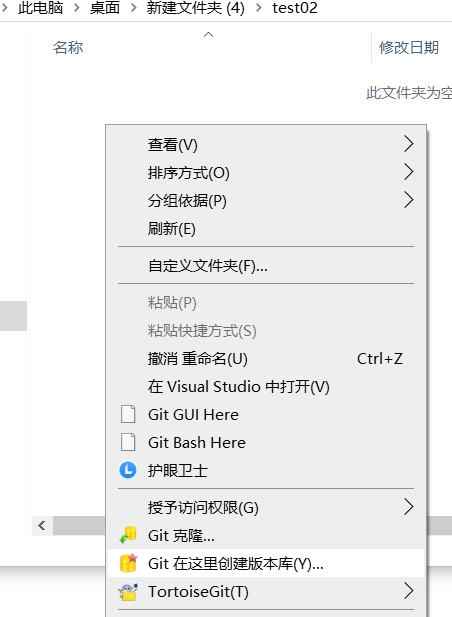
初始化完成
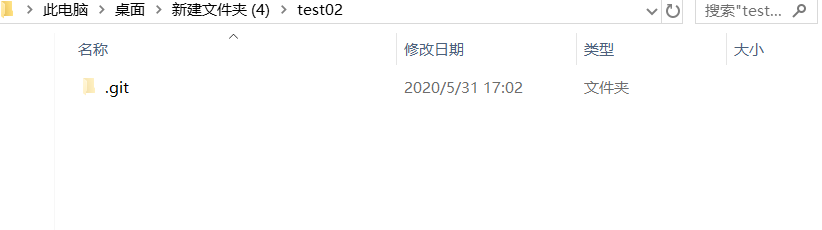
2.新建文件夹,右键文件夹选中TortoiseGit点击添加
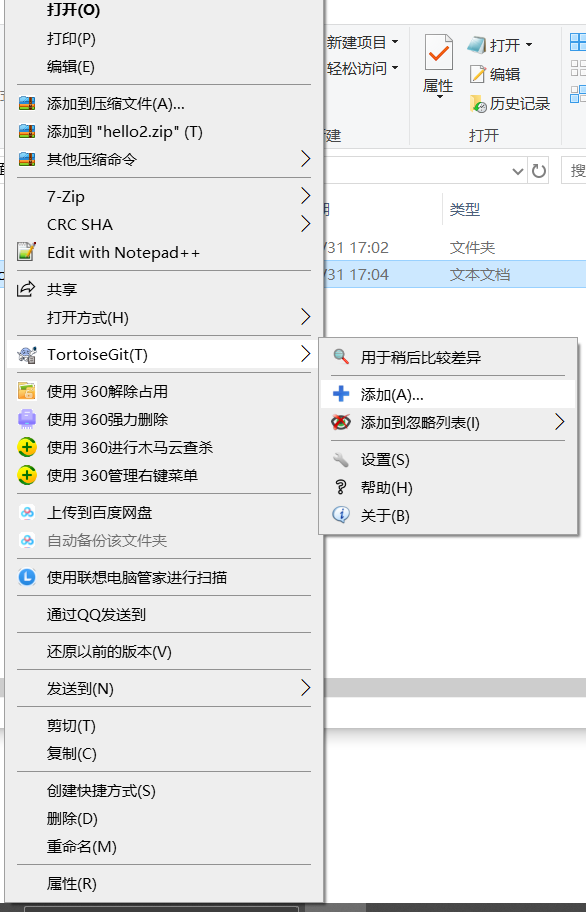
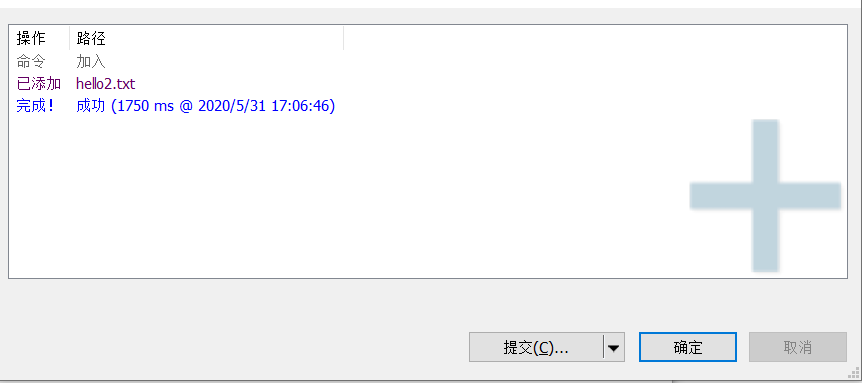
再点击提交,提交到git的仓库,然后再点击推送,推送到github的远程仓库,这时就成功的推送到远程仓库了。
我建议用第二种方式推送到github的远程仓库,比较方便快捷。
转载此文请标明出处:https://zhajianliang.github.io
1 | ~~文字~~//快捷键:Alt+Shift+5 |
删除线
1 | *文字*//快捷键:Ctrl+I |
斜体
1 | **文字**//快捷键:Ctrl+B |
加粗
1 | ***斜体+加粗*** |
斜体+加粗
1 | <u>文字</u>//快捷键Ctrl+u |
下划线
1 | # 一级标题 快捷键 ctrl+1 |
白菜
青菜
| 语文 | 数学 | 英语 | 政治 |
|---|---|---|---|
| 58 | 95 | 125 | 100 |
| 45 | 98 | 65 | 86 |
1 | include<stdio.h> |
1 | //(快捷键:Ctrl+Shift+` |
c++是一类面向对面的编程语言。
1 |  |

1 | [我的网址](https://zhajianliang.github.io)//显示的时候只会显示我的网址,点我的网址就会跳转到 |
效果:
1 | >作者 李白 |
效果如下:
作者 李白
作者 王维
作者 白居易
缺失模块。
1、请确保node版本大于6.2
2、在博客根目录(注意不是yilia根目录)执行以下命令:
npm i hexo-generator-json-content --save
3、在根目录_config.yml里添加配置:
jsonContent:
meta: false
pages: false
posts:
title: true
date: true
path: true
text: false
raw: false
content: false
slug: false
updated: false
comments: false
link: false
permalink: false
excerpt: false
categories: false
tags: true